ERC721R: 一个新的ERC721合约,通过随机铸造避免对稀有属性的抢购
翻译:团长(https://twitter.com/quentangle_)
译注:目前有多个名为ERC721R的ERC721扩展协议,更知名的那个721R在这里。
Or:如果不用ERC721R,如何抢购稀有属性
TLDR: 这里是ERC721R代码库的链接。
简介:运气
Mphers是第一个mfers衍生品,由于它也是Phunks的衍生品,我非常想拥有一个。
我特别想要一个外星人。他们看起来最酷,而且在6,969个系列中只有8个。而我得到了一个!
虽然我在推特上说得不是很清楚,但我的意思是,我很幸运地想出了如何在不需要运气加持的情况下100%保证我可以得到一个外星人。
请继续阅读我是如何做到的,你也可以做到,而如果你是一个开发者,你可以如何防止这种情况的发生!
如何在不需要运气的情况下铸造出稀有的NFTs
铸造稀有NFT的关键是提前知道每个稀有代币的ID。
例如,如果我知道我的外星人是#4002,我所要做的就是刷新铸币页面,直到我看到#3992已经被铸成,然后立即铸成10个mphers。
我是怎么知道4002号是外星人的呢?让我们回溯一下我的步骤。
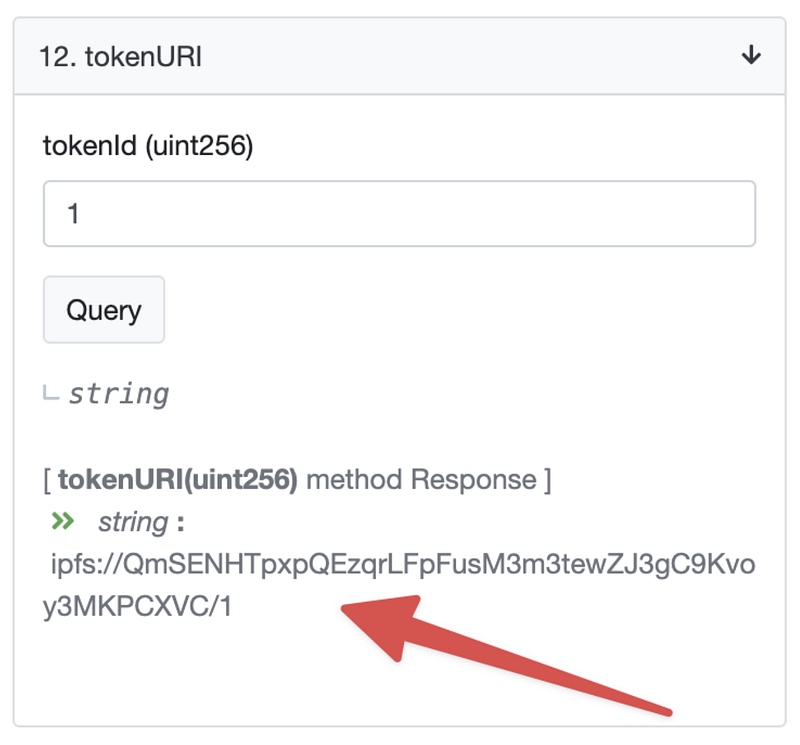
首先,进入mpher合约的Etherscan页面,查找一个已经被铸造的代币的tokenURI,即1号代币。
正如你所看到的,mphers,像许多合约一样,通过将tokenID与IPFS哈希值相结合来构建元数据URI。
这种方法的好处是,它在每个URI中为你提供了整个集合的出处,虽然URI可以改变,但这样做会影响到每个人,并且是公开的。
作为对比,想象一下如果tokenURI不包含来源哈希值,例如https://mphers.art/api?tokenId=1。作为一个玩家,你永远无法确定开发者会不会偷偷地改变1号的元数据。
然而,如果你有一个API,你可以说 “如果#4002没有被铸造,不要显示任何关于它的信息”,如果你走IPFS路线,你就不能这样做。
一旦元数据显示出来(在mpfers的情况下是即时的),你可以查询任何token的元数据,无论它是否已经被铸造。
只要把上面URI中的尾部 “1”替换成你想要的id即可。
这些元数据文件为我们提供了具有指定id的mpher的所有属性。例如,在我的外星人的情况下。
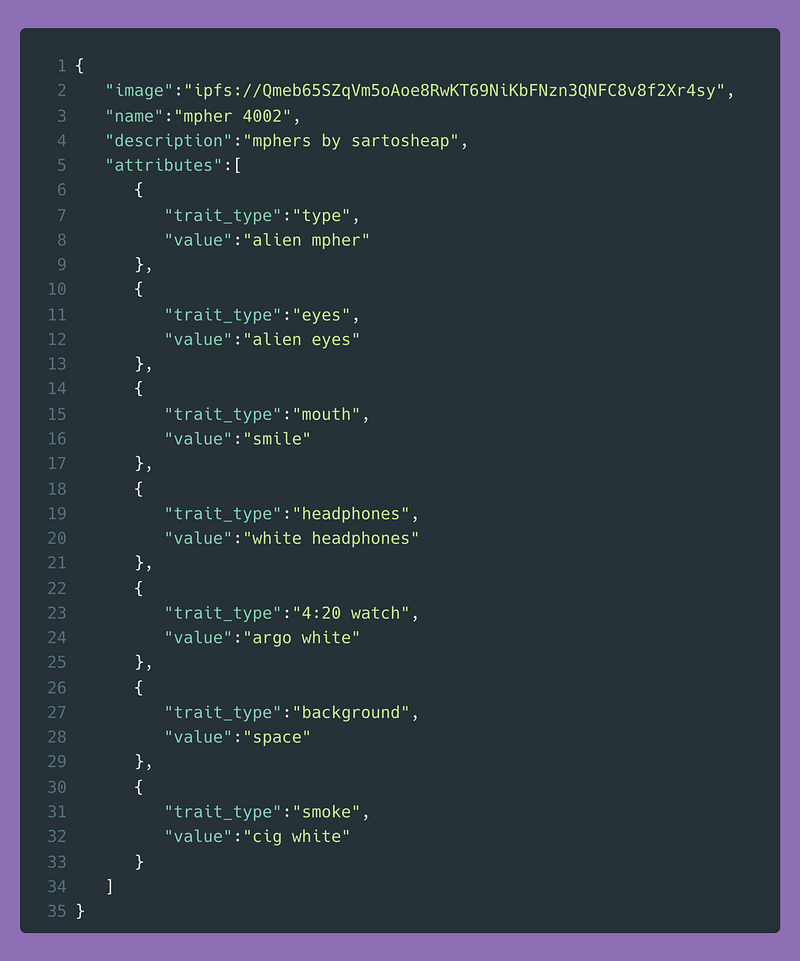
为了找到外星人,我们只需要在所有的元数据文件中搜索 “alien mpher “这个字符串。
接下来,下载6,969个元数据文件。这里我用的是OpenSea的IPFS网关,但如果效果更好的话,你可以试试ipfs.io或其他来源。

这段代码使用curl来下载文件,一次10个。快速下载数以千计的文件可能是不稳定的,所以你可能会出现一些重复的文件或错误。但是,如果你仔细操作,你应该能够得到所有的文件(对于我要做的事来说这不是问题)。
现在你已经把文件放在一个目录里了,只需用grep查找外星人alien:

出现的数字是包含 “alien mpher”的文件名称,因此是外星人本身的ID。
整个过程需要不到10分钟。而且你可以在现在正在造币的许多NFT上使用这种技术。
在实践中,在准确的时刻手动铸币来获得外星人并不是完全不可行的,特别是在代币铸造很快的时候。如果你真的想用这种方法 “搞个大的”,你应该写一个机器人,每秒轮询totalSupply(),在准确的时刻自动提交铸造交易。
如果你想 “搞个更大的”,你可以在mempool中寻找你需要的代币,甚至在它被铸造之前,让你的铸造交易进入同一个区块!
然而,根据我的经验,这种的方法足以赢得99%的时间,但不是100%的时间。
“我是不是一直在被人耍?”
如果你现在刚刚了解到这一点,你可能会问自己这个问题。
如果有人用这种技术铸造你想要的东西,你没有机会获得,这种想法令人痛心。
但是,你没有机会吗?在某种程度上,你和其他人有同样的机会!
以我为例。我利用公共信息自己想出了这个办法,并利用免费的开源工具将其付诸实施。任何人都可以这样做,一般来说,如果你不在铸币前调查合约是如何运作的,你将会遇到比这更糟糕的问题。
mpher的铸币是100%的公平。
不过,虽然这是一个公平的游戏,但 “抢购外星人”可能不是每个人都想玩的游戏。
相反,人们可能会在玩 “铸币抽奖mint lottery”的游戏中获得更多的乐趣,在这个游戏中,代币的分配是随机的,不可能比那些只是点击 “mint”按钮的人获得优势。
我们可能如何做到这一点?
公平的随机造币
对于Fashion Hat Punks,我的目标是在不牺牲公平性的情况下创造一个随机的铸币体验。在我看来,一个可预测的铸币远比一个不公平的铸币好。最重要的是,必须让参与者处于平等地位。
不幸的是,创造随机体验的最常见方式 — 所谓的铸币后 “揭秘” — 是非常不公平的。它的工作原理是这样的:
- 代币元数据在铸币过程中是无法访问的。tokenURI()指向所有id的同一个空白JSON文件。
- 一旦所有的代币被铸造,合约所有者就会将IPFS的哈希值更新为真正的元数据。
- 没有办法验证合约所有者如何选择哪些tokenID得到哪些元数据,结果似乎是随机的。
在这里,设置元数据的人显然比正在造币的人有巨大的优势,因为他们独自决定谁得到了什么!与mpher 铸造不同,这里的情况是你实际上没有机会竞争。
但是,如果是一个知名的、值得信赖的、有长期记录的、可以找到开发团队呢。在这种情况下,揭示可以吗?
不!没有人可以被信任拥有这种权力。即使有人不是有意识地想作弊,他们也会像其他人一样带来无意识的偏见。除此之外,他们可能只是犯了一个错误,直到为时已晚才意识到这一点。
你也不应该相信自己。想象一下,你做了一次揭示,你觉得自己做得很好(没有什么是100%的!),但不知为何,你最后得到了最稀有的NFT。那会不会感觉有点奇怪?你确定你值得拥有它吗?就个人而言,作为一个NFT开发者,我不希望处于这种情况。
底线是这样的:揭示不是最佳的方式*。
*除非:它们是以无信任的方式进行的,这意味着每个人都可以验证它们的公平性,而不需要信任开发者(你永远不应该这样做)。
为了实现无信任的揭示,你需要一种方法来证明揭示是公平的 — 通常是让揭示发生在链上,并由任何人都无法控制的随机性来驱动(例如通过Chainlink)。
Tubby Cats在这种揭示方式上做得很好,我建议你看看他们的合约和启动。他们的揭示也很酷,因为它是渐进式的 — 你不必等到铸造的最后才知道你得到了什么。
一般来说,不信任的缺点是很难做对 — @DefiLlama在他的发布会反思中这样说。
在写合约的时候,我让它尽可能地无信任,尽可能地把信任移到团队中。
其原因是,我认为每个参与者都必须知道游戏规则,并且知道这些规则不会从他们手下被改变(每个人都应该有完整的信息来做决定,如果过程在中间被改变,那就会形成拥有特权信息的群体),而信任最小化很重要,因为这是智能合约的全部理由(而且即使团队被破坏,它也不可能被破解)。然而这是一个巨大的错误,因为它大大降低了我们的灵活性和我们可以采取的行动。
而@DefiLlama是一个顶级的开发者。如果最大化不信任给他带来了这么多的麻烦,想象一下它会给你带来什么吧!
因此,我的建议是使用一个妥协的解决方案,但是在99%的情况下仍然足够,而且更容易实现:随机token分配。
进入ERC721R:一个完全符合IERC721的实现,以伪随机的方式选择代币ID
ERC721R实现了揭示的反面:我们不是确定地铸造tokenID并随机地分配元数据,而是随机地铸造tokenID并确定地分配元数据。
这使我们能够在铸币前揭示所有的元数据,同时仍然最大限度地减少科学家的抢购机会。
要使用它,请将合约复制到你的项目目录(对不起,还没有NPM包),导入它,并使用这段代码:

ERC721R是如何工作的?
首先,免责声明:与无信任揭示不同,ERC721R不是真正的随机。在这个意义上,它创造了我们在mpher情况下看到的同样的 “游戏”,即买家可以使用公开的信息来“优化”铸造。然而,在ERC721R的情况下,这个游戏明显更难。
想要用程序利用ERC721R,你需要能够通过这些输入来预测哈希值:
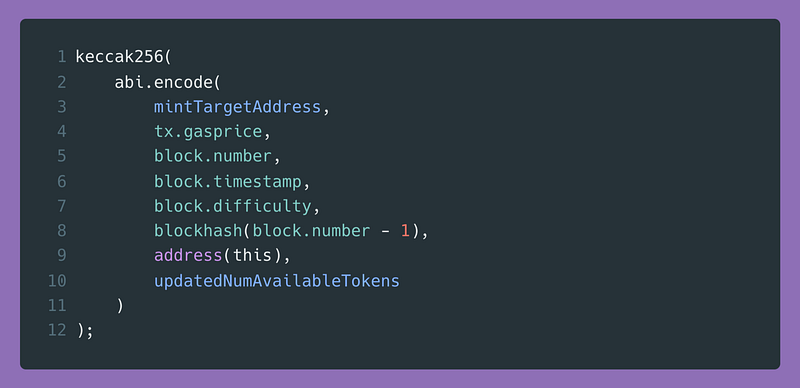
对于普通人来说,这是不可能的,因为这需要知道你的铸币区块的时间戳,而你没有机会获得这些信息。
一个能够控制区块开采时间的矿工(因此可以影响时间戳)理论上可以做到这一点,但即使如此,他们也必须将时间戳设置为未来的一个值,而且无论他们在做什么,都取决于前一个区块的哈希值,该值在下一个区块开采时约10秒后失效。
我相信这种伪随机性是 “足够好的”,但如果有大笔资金在手,它就会被100%确定地玩弄于股掌之间,所以要小心!当然,它所取代的系统 — 可预测的铸造 — 也会被操纵。
tokenID的选择本身发生在我从CryptoPhunksV2复制的Fisher-Yates洗牌算法的现代版本的一个非常聪明的实现中。
为了理解它,首先考虑笨办法解决方案:(下面假设有10,000个项目的集合)
- 创建一个包含数字0–9999的数组
- 当你想铸造一个代币时,从数组中随机选择一个,并使用该值作为你的tokenID。
- 从数组中移除该值,并将其长度减少1,这样缩短后的数组中的每个索引都对应于一个可用的tokenID。
这很有效,但它花费了太多的gas,因为改变数组的长度和存储一个充满非零值的巨大数组是很昂贵的。
我们怎样才能避免这两种情况呢?如果我们转而从一个包含10000个零的数组开始呢,这样做的成本很低。现在让我们用这个数组中的每个索引来代表一个id。
假设我们随机选择索引#6500 — #6500将是我们的token id,我们将通过(例如)用1替换索引#6500中的0来表示索引#6500已经被使用。
但是如果我们再次选择#6500会发生什么呢?我们会观察到一个1,表明#6500被使用了,但是然后呢?我们不能简单地 “再次滚动”,因为这将使gas变得不可预测和高,特别是对于后来的铸造。
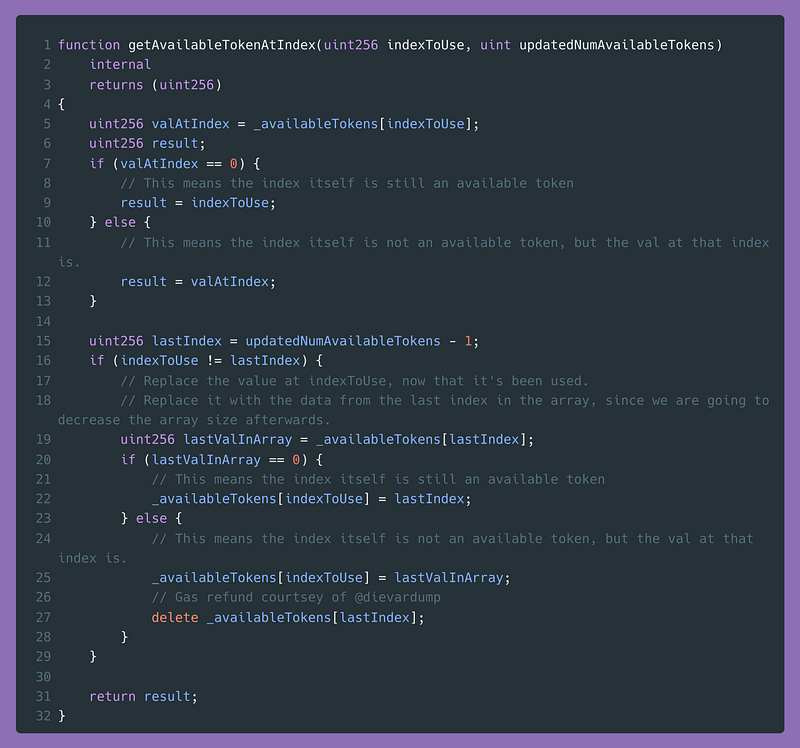
现代Fisher-Yates的天才之处在于,它为我们提供了100%选择可用tokenID的机制,而不需要花费成本去维护一个单独的列表。下面是它的工作原理:
- 创建一个包含10,000个零的数组。
- 用10,000的值初始化一个
uint numAvailableTokens。 - 在0和
numAvailableTokens-1之间随机挑选一个数字。 - 假设你选择了#6500-查看索引#6500。如果值是0,#6500就是你的下一个tokenID。如果该值为非零,那么索引#6500的值就是你的下一个tokenID(开始变得奇怪了!)。
- 现在,看看数组中的最后一个值,也就是索引
numAvailableTokens-1的值。如果该值为0,则将索引#6500的值更新为数组中的最后一个索引(如果是第一个代币,则为#9999)。如果数组中的最后一个值不是0,则更新索引#6500来存储这个最后的非零值。 - 将
numAvailableTokens减去1。 - 重复3–6,得到下一个可用tokenID。
就这样!数组的大小保持不变,但我们能够可靠地选择一个可用的id。这里是Solidity代码:
不幸的是,这种算法仍然比领先的连续铸币解决方案ERC721A使用更多的gas。
这在一次交易中铸造多个代币时最为明显 — 例如,在ERC721R上铸造10个代币的成本比ERC721A多5倍。也就是说,ERC721A已经比ERC721R优化了很多,所以可能还有改进的空间。
结论
你可以选择:
- ERC721A:买家支付较低的gas,但必须花时间和精力设计和执行一个有竞争力的造币策略,或接受较差的造币结果。
- ERC721R: gas较高,但除了最极端的情况外,只需点击按钮的简易造币策略是最佳选择。如果矿工对ERC721R进行操纵,那就是两败俱伤:较高的gas和大量的工作来竞争。
- ERC721A+standard reveal:gas低,但不可验证的公平。请不要这样做!
- ERC721A + trustless reveal:如果操作得当,这是最好的解决方案,对设计者来说有很大的挑战,有可能出现难以纠正的错误。
